
インデックスを使うと何故早くなるのか
本ページではORACLEにおいてインデックスを使うと何故クエリが早くなるのか、またはなぜ速くならないのかを説明します。 なお、本ページでは索引構成表やビットマップインデックス等の特殊なデータ構造を持つオブジェクトは考慮しておらず一般的なテーブルとインデックスを想定しています。前提知識
インデックスを使うとなぜ速くなるのかを理解するためには以下の前提を理解している必要があります。・ディスクアクセスはCPUアクセスと比較すると非常に遅い
一般的にはCPU処理時間がナノ秒単位であるのに対してディスクのアクセス時間はミリ秒単位であり、ディスクはCPUに比べて100万倍程度処理が遅いとされています。 したがって、クエリの処理時間はディスクアクセスが最も少ない実行計画が最も高速となる可能性が高いと考えられます。
・I/Oの単位はブロックである
ORACLEのI/Oの最小単位はブロックなので必要なデータサイズが1bitだったとしてもブロックサイズが8Kであれば8KのI/Oが発生します。
・テーブルデータはソートされていない
ORACLEのテーブルに格納されているデータはソートされていないためどこにどのようなデータが入っているかは分かりません。
・インデックスはBツリー構造で構築される
ORACLEのインデックスはインデックスキーによるBツリー構造になっておりデータがソートされた状態で格納されます。
インデックス有無による検索処理の差異
ここでは以下のテーブルと検索条件を仮定します。- テーブルのブロックサイズは8K
- テーブルは1000件のデータを持ち、1ブロックあたり10行のデータを格納できる(合計100ブロックでサイズは800K)
- 検索条件は1000件中1件だけヒットする条件である
インデックスがない場合
ORACLEのテーブルデータはソートされていないため検索条件に合致するデータを調べるためには100ブロック(800K)のI/Oが発生します(テーブルフルスキャン)。 つまり、インデックスがないテーブルを検索する場合検索条件の内容によらず全てのブロックを読み込まなければ正しい検索結果が戻せません。
インデックスがある場合
上記テーブルに対して検索条件列に対してインデックスを作成したところ以下のようなBツリー構造のインデックスが作成されたとします。線がつながっているブロックに対してはブロック内にポインタ情報(rowid)が記録されているためダイレクトにそのブロックを読みにいくことができます。
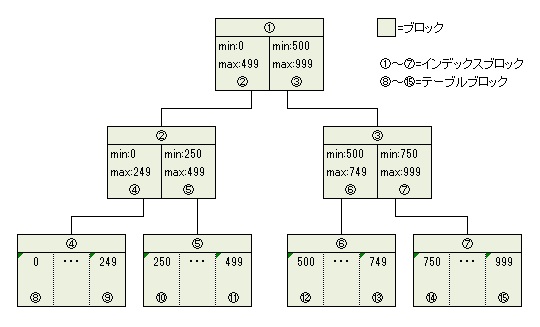 |
テーブルフルスキャンのほうが早い場合
上記ケースではインデックスを使用するほうがI/Oが減少するためパフォーマンスが向上すると記載しましたが、 検索条件が「値が1~500のデータ」(選択率50%)という検索条件だった場合インデックススキャンのほうがI/O量が減少するとしても大抵の場合テーブルフルスキャンのほうが早くなります。 これはインデックスによるアクセスの場合は必ず1ブロック単位でI/Oが発生するのに対し、テーブルフルスキャンの場合は複数ブロックを一度に読み込むことができるためです。 この一度に読み込むブロック数は初期化パラメータ「db_file_multiblock_read_count」の値で決まります。同じI/O量であればインデックススキャンよりもテーブルフルスキャンのほうが圧倒的に速いですが、 インデックススキャンよりもテーブルフルスキャンのほうが早くなる割合はデータ構造やディスク性能等に大きく影響を受けるため一概には言えませんが20%程度を目安にするとよいと思われます。
非効率なインデックス
検索条件の選択率以外に、以下のような場合はインデックスが遅くなる場合があります。インデックスキーが多い、または長い
ブロックサイズは一定でありブロック内に格納できるデータには限りがあるため、インデックスのキー列が多い場合やキー列が非常に長いような場合インデックスを構成するブロック数が多くなり検索が遅くなります。 特にchar型は固定長のため、定義サイズが大きく実際に格納されているデータが短い場合は無駄な空白領域でブロックを占有してしまうので可能であればchar型ではなくvarchar2型の使用を検討します。
インデックスのクラスタ化係数が高い
クラスタ化係数とはインデックスのリーフブロックに記録されているテーブルブロックへのポインタの一意な数がどの程度まとまっているかを表した値で統計情報を取得するとDBA_INDEXESのCLUSTERING_FACTOR列で確認することができます。 インデックスキーが同じデータが複数のブロックに分散されて格納されている場合はクラスタ係数が高く(悪く)なり、クラスタ化係数の最も望ましい状態は全リーフブロック数の値で最も非効率な状態ではテーブルの全行数の値です。
1テーブルに対して複数インデックスが定義されている場合全てのクラスタ化係数を最適化することは難しいですが、頻繁に使用されているインデックスやパフォーマンスが悪いクエリで使用されているインデックスのクラスタ化係数が悪い場合以下を検討します。
- キー列のパーティション化
- テーブルデータの再作成(create table XXX as select * from YYY order by <キー列>等でデータをソートして作り直す)
インデックスの断片化
インデックスはキー列が更新されるたびに基本的には断片化が進みパフォーマンスが劣化します。断片化はインデックスの再構築(alter index XXX rebuild)をすることで解消されます。
その他の使用用途
インデックスを利用することで単純な検索以外にも以下のようなケースで高速化することができます。・インデックスファストフルスキャン
テーブルのブロック数と比較するとインデックスのブロック数は少なくなる場合が多いため、インデックスブロックの読み込みのみで対処できる処理はテーブルにはアクセスせず、インデックスブロックのみフルスキャンすることで処理を高速化できるものがあります。 通常のインデックススキャンとは異なり、テーブルフルスキャン同様に複数ブロックを同時に読み込む処理を全インデックスブロックに対して実施する処理をインデックスファストフルキャンと呼びます。 インデックスファストフルキャンを利用するには条件がありますが利用できる代表的な処理には以下のようなものがあります。
・テーブル件数のカウント(select count(*) from XXX 等)
・インデックスのキー値のみを戻すクエリ(select <インデックスのキー値>from XXX等)
なお、インデックスブロックにはNULL値のデータが格納されないためNOT NULLやプライマリキー制約が付いた列のインデックスである必要があります。
・max値、min値の取得
インデックスのブロックはソートされているためキー値の最小値、最大値はインデックスブロックをたどれば容易に値を取得することができます。
マニュアル
・概要・パフォーマンス・チューニングガイド
 折りたたみ
折りたたみ 展開
展開